![]() Webinar: Building a localizations workflow for winning transactional & marketing emails Watch now
Webinar: Building a localizations workflow for winning transactional & marketing emails Watch now
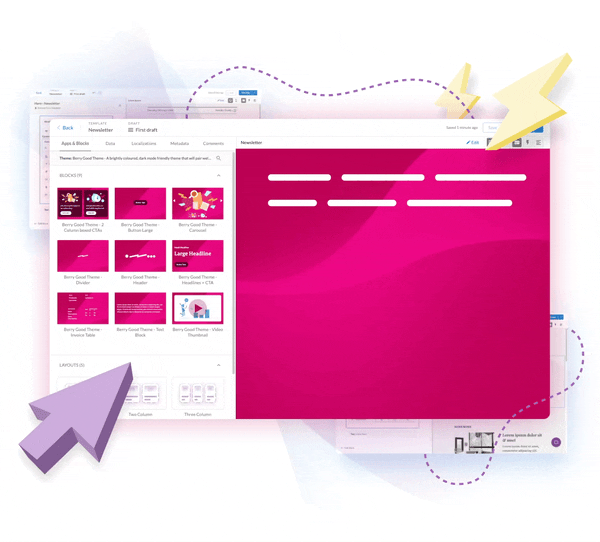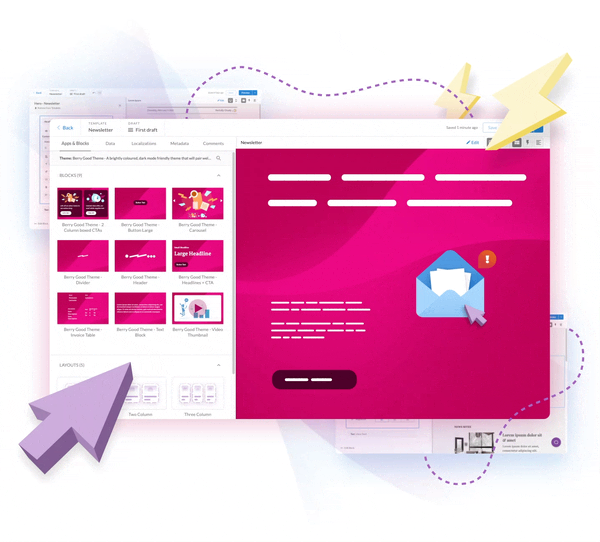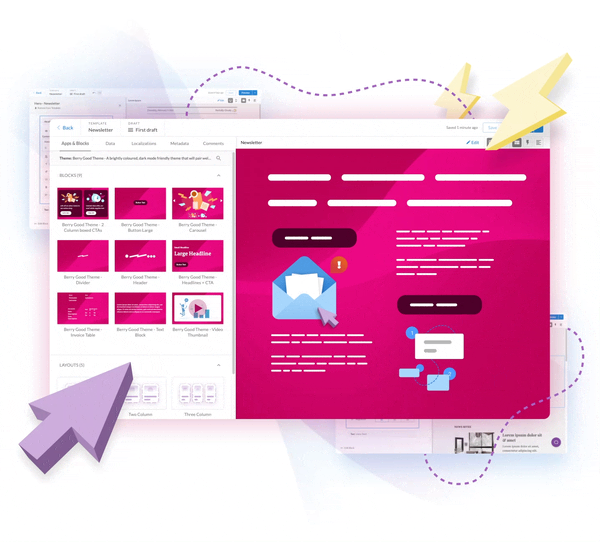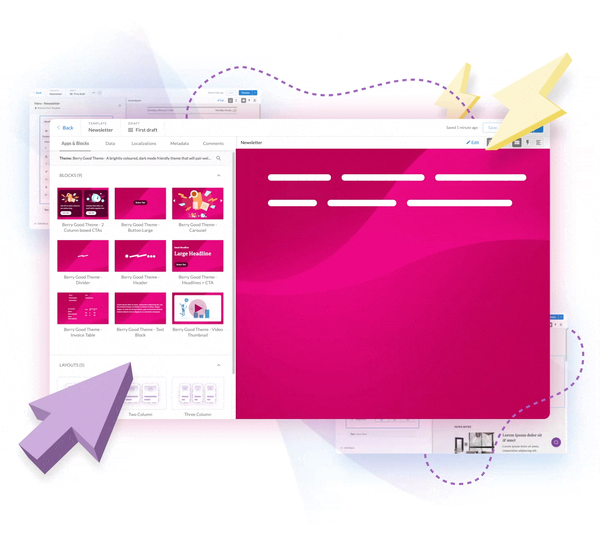
A Powerful, No-Code
Email Builder
STREAMLINE AND SCALE
- Create custom email templates in minutes — without writing code
- Get peace of mind with default mobile responsiveness
- Explore flexible integrations with one or multiple ESPs
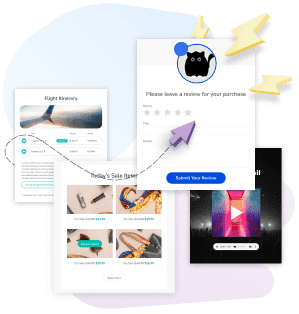
Apps in Email:
AMP Made Easy
INNOVATE AND GROW
- Deliver live, dynamic, and interactive
email content - Remove friction points and create winning inbox experiences
- Empower in-email actions to boost engagement and conversions